Describe continuous, ordinal and nominal data. Provide examples of each. Describe a model of your own construction that incorporates variables of each type of data. You are perfectly welcome to describe your model using english rather than mathematical notation if you prefer. Include hypothetical variables that represent your features and target.
Continuous data is numerical data that can hold the value of any decimal number. For example, average temperatures in a given area are continuous data points because they can take any decimal value. Ordinal data is a categorical data type in which data points take on the values of ordered categories. An example of ordinal data could be a survey question to citizens of a given city asking them to rank overall city sanitation on a scale from 1 - 5. Because these results are distinctly ordered, with 1 being the worst and 5 the best, this represents an ordinal data type. Nominal data is also categorical like ordinal data, however it is not ordered in any meaningfull way. An example of this could be hair color or home nation. While these data points will fall into certain categories (brown hair, USA, etc.), the order of these categories has no meaning in the analysis of this data.
Suppose we are constructing a model in an attempt to predict a countries GDP based on a number of variables of each type. It might look like this: Y = X0 + X1 + X2 + X3 + X4 Where Y represents our target, GDP, and X1, X2, X3, and X4 represent our features. In this case X1 is a continuous variable, life expectancy. X2 and X3 are ordinal variables represented on a scale of 1 - 10, economic development and living standards respectively. X4 is a nominal variable, continent. Of course, X0 is the intercept of our regression line.
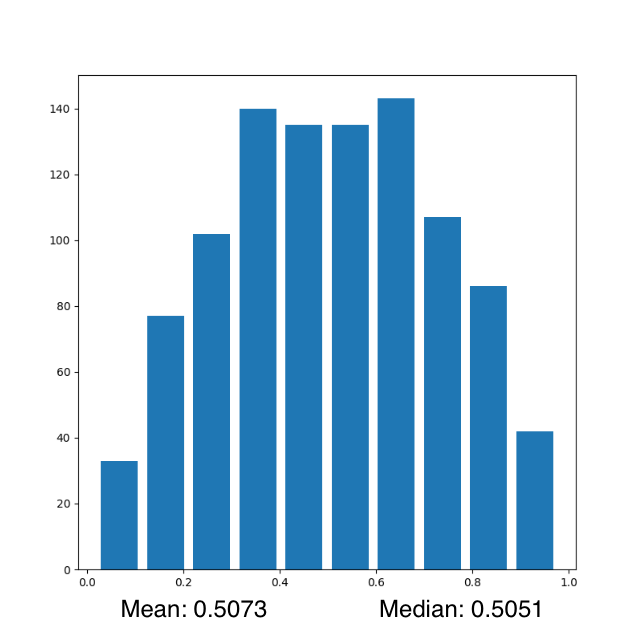
Comment out the seed from your randomly generated data set of 1000 observations and use the beta distribution to produce a plot that has a mean that approximates the 50th percentile. Also produce both a right skewed and left skewed plot by modifying the alpha and beta parameters from the distribution. Be sure to modify the widths of your columns in order to improve legibility of the bins (intervals). Include the mean and median for all three plots.
Plot with mean approxiating 50th percentile:
n = 1000
alpha = 2.0
beta = 2.0
x1 = np.random.beta(alpha, beta, size=n)
plt.figure(figsize=(8, 8))
plt.hist(x1, rwidth=0.8)
The above code will result in a histogram with aprroximate normal distribution. Thus, the resulting mean should be quite close to the 50th percentile. An example of a histogram generated by running this code is as follows: Plot 1
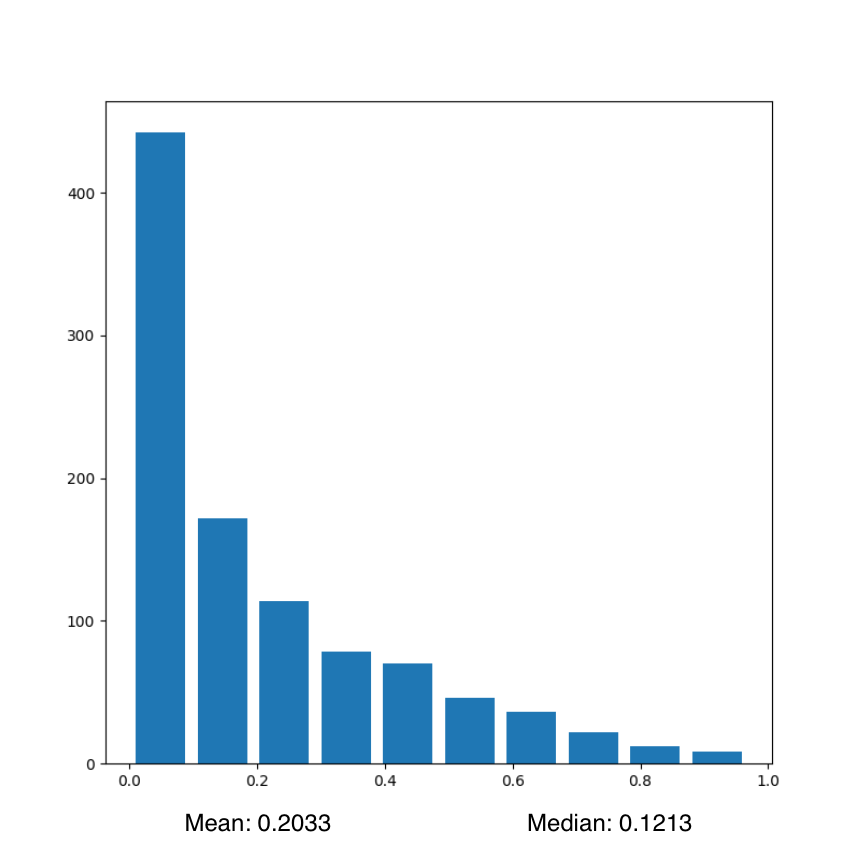
Plot with right skew:
n = 1000
alpha = 0.5
beta = 2.0
x1 = np.random.beta(alpha, beta, size=n)
plt.figure(figsize=(8, 8))
plt.hist(x1, rwidth=0.8)
The above code will result in a histogram with right skewed data. An example of a histogram generated by running this code is as follows: Plot 2
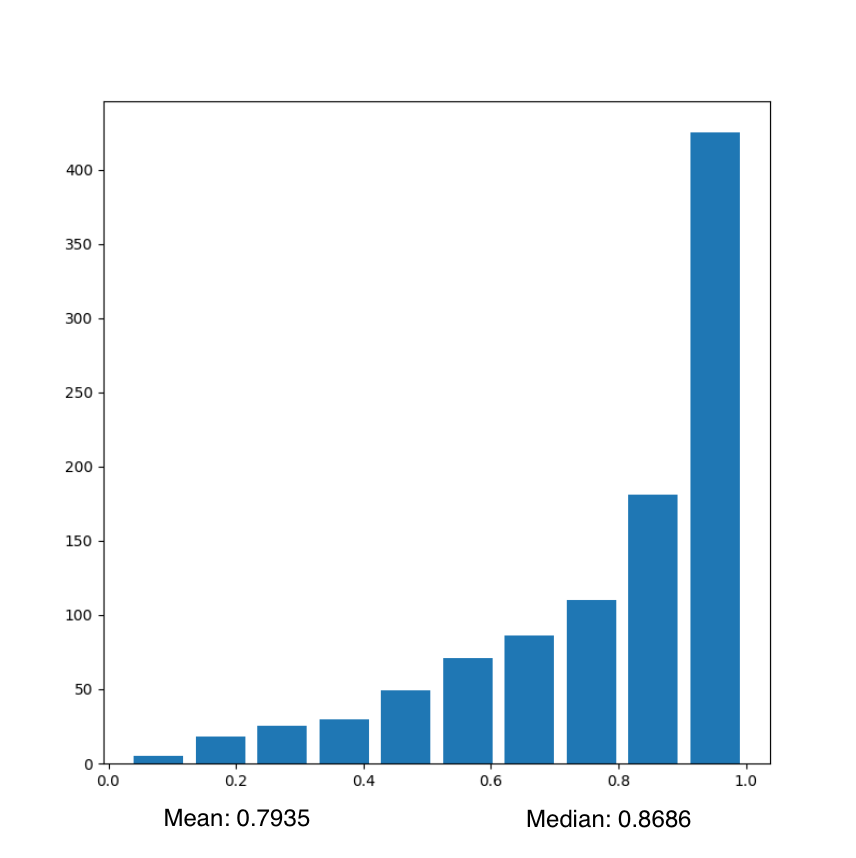
Plot with left skew:
n = 1000
alpha = 2.0
beta = 0.5
x1 = np.random.beta(alpha, beta, size=n)
plt.figure(figsize=(8, 8))
plt.hist(x1, rwidth=0.8)
The above code will result in a histogram with left skewed data. An example of a histogram generated by running this code is as follows: Plot 3
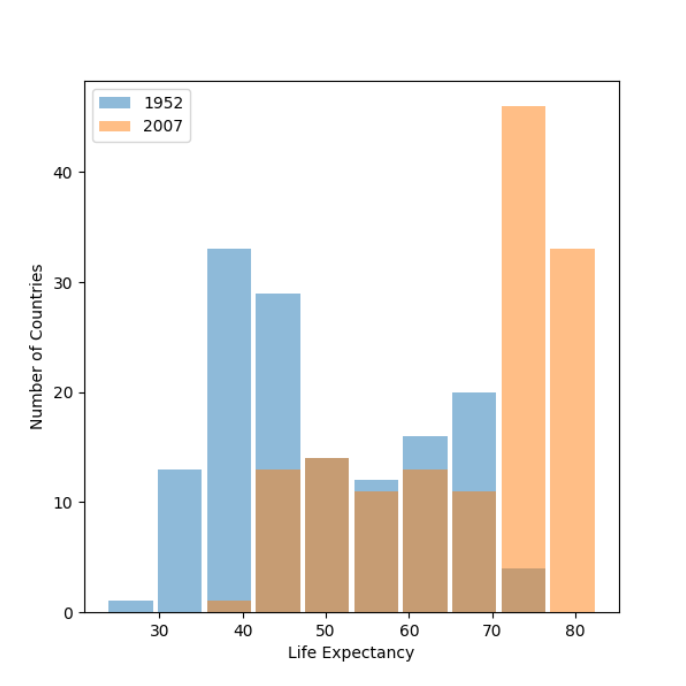
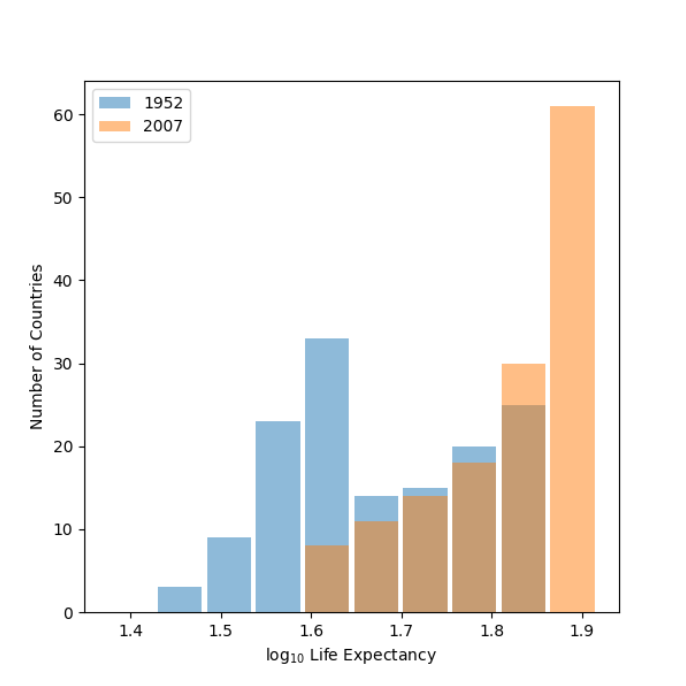
Using the gapminder data set, produce two overlapping histograms within the same plot describing life expectancy in 1952 and 2007. Plot the overlapping histograms using both the raw data and then after applying a logarithmic transformation (np.log10() is fine). Which of the two resulting plots best communicates the change in life expectancy amongst all of these countries from 1952 to 2007?
Plot with raw data:
df = pd.read_csv('gapminder.tsv', sep='\t')
idx52 = df['year'] == 1952
df52 = df[idx52]
idx07 = df['year'] == 2007
df07 = df[idx07]
plt.figure(figsize=(6, 6))
plt.hist(df52['lifeExp'], rwidth=0.9, label=1952, alpha=0.5)
plt.hist(df07['lifeExp'], rwidth=0.9, label=2007, alpha=0.5)
plt.xlabel('Life Expectancy')
plt.ylabel('Number of Countries')
plt.legend()
plt.show()
Plot with logarithmic transformation:
plt.figure(figsize=(6, 6))
plt.hist(np.log10(df52['lifeExp']), rwidth=0.9, label=1952, alpha=0.5)
plt.hist(np.log10(df07['lifeExp']), rwidth=0.9, label=2007, alpha=0.5)
plt.xlabel('$\log_{10}$ Life Expectancy')
plt.ylabel('Number of Countries')
plt.legend()
plt.show()
After looking at both plots, although they look quite similar I would say that the logarithmic transformation plot best communicates the change in life expectancy in all countries between 1952 and 2007. This is because the trends in data in both years seem to be a bit easier to read and the amount of high life expectancy countries in 2007 relative to 1952 is more pronounced than in the raw data plot.
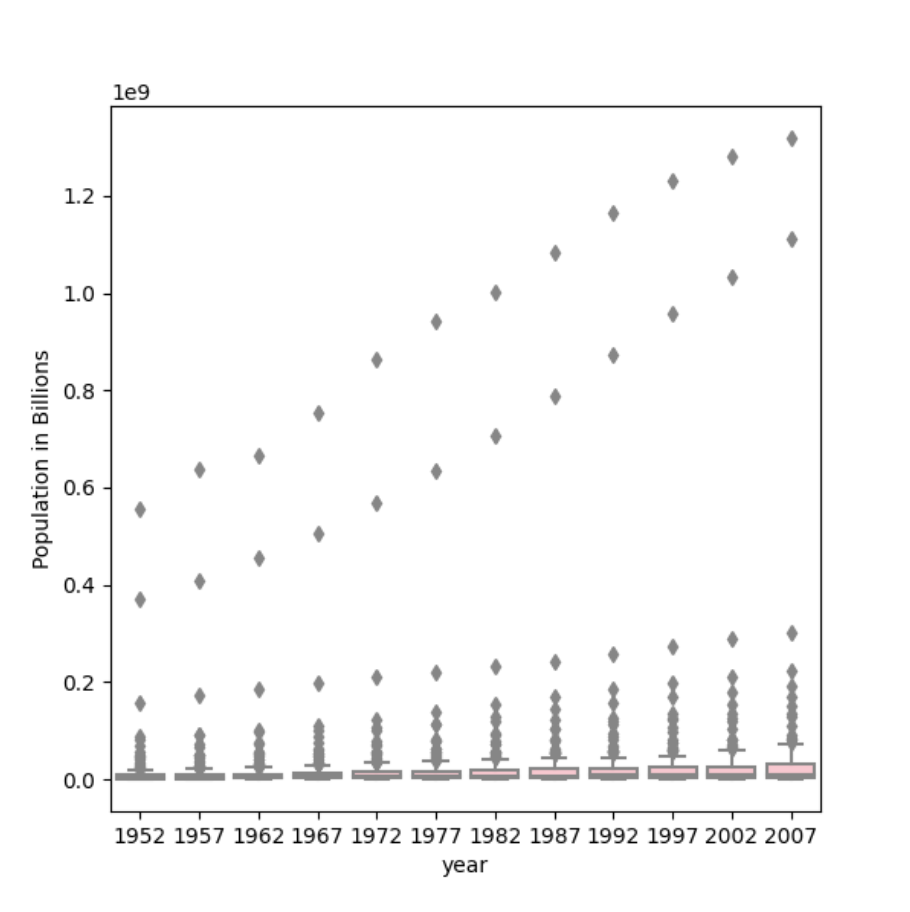
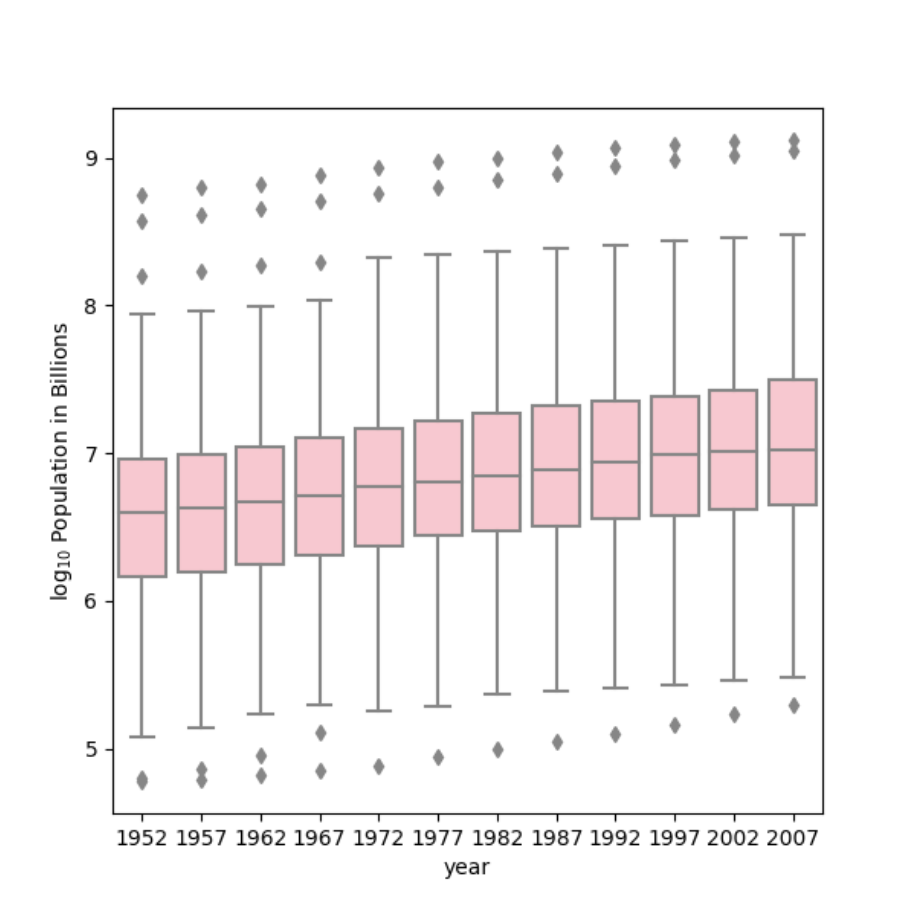
Using the seaborn library of functions, produce a box and whiskers plot of population for all countries at the given 5-year intervals. Also apply a logarithmic transformation to this data and produce a second plot. Which of the two resulting box and whiskers plots best communicates the change in population amongst all of these countries from 1952 to 2007?
Plot with raw data:
plt.figure(figsize=(6, 6))
sns.boxplot(x=df['year'], y=df['pop'], color='pink')
plt.ylabel('Population in Billions')
Plot with logarithmic transformation:
plt.figure(figsize=(6, 6))
sns.boxplot(x=df['year'], y=np.log10(df['pop']), color='pink')
plt.ylabel('$\log_{10}$ Population in Billions')
It is more obvious than in the last question which plot is better at communicating the change in population. Because of the presence of far outliers in the first plot, the actual box plot which has our useful data points is barely visible. While this is true, you still can see population growth over time in this first plot. However, the second plot is a much better representation of our data because it gets rid of those outliers and presents the boxes visibly. Because the plot is cleaner, easier to read, and still shows the upward growth in population, it is the best representation of our data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}