I first set up my workspace by importing the libraries and functions and creating the commands I will need:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler as SS
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import train_test_split as tts
from sklearn.neighbors import KNeighborsClassifier as KNN
def DoKFold(model, X, y, k=20, standardize = False, random_state = 146, reshape = False):
from sklearn.model_selection import KFold
kf = KFold(n_splits=k, shuffle=True, random_state=random_state)
if standardize:
from sklearn.preprocessing import StandardScaler as SS
ss = SS()
train_scores = []
test_scores = []
train_mse = []
test_mse = []
for idxTrain, idxTest in kf.split(X):
ytrain = y[idxTrain]
ytest = y[idxTest]
if reshape:
Xtrain = X[idxTrain]
Xtest = X[idxTest]
Xtrain = np.reshape(Xtrain,(-1, 1))
Xtest = np.reshape(Xtest,(-1, 1))
else:
Xtrain = X[idxTrain,:]
Xtest = X[idxTest,:]
if standardize:
Xtrain = ss.fit_transform(Xtrain)
Xtest = ss.transform(Xtest)
model.fit(Xtrain, ytrain)
train_scores.append(model.score(Xtrain, ytrain))
test_scores.append(model.score(Xtest, ytest))
ytrain_pred = model.predict(Xtrain)
ytest_pred = model.predict(Xtest)
train_mse.append(np.mean((ytrain - ytrain_pred)**2))
test_mse.append(np.mean((ytest - ytest_pred)**2))
return train_scores,test_scores,train_mse,test_mse
def GetData(scale=False):
Xtrain, Xtest, ytrain, ytest = tts(X, y, test_size=0.4)
ss = StandardScaler()
if scale:
Xtrain = ss.fit_transform(Xtrain)
Xtest = ss.transform(Xtest)
return Xtrain, Xtest, ytrain, ytest
def CompareClasses(actual, predicted, names=None):
accuracy = sum(actual == predicted) / actual.shape[0]
classes = pd.DataFrame(columns=['Actual', 'Predicted'])
classes['Actual'] = actual
classes['Predicted'] = predicted
conf_mat = pd.crosstab(classes['Predicted'], classes['Actual'])
# Relabel the rows/columns if names was provided
if type(names) != type(None):
conf_mat.index = y
conf_mat.index.name = 'Predicted'
conf_mat.columns = X
conf_mat.columns.name = 'Actual'
print('Accuracy = ' + format(accuracy, '.2f'))
return conf_mat, accuracy
Next, before we begin to analyze our data, I had to read the desired file into the workspace:
url = "https://raw.githubusercontent.com/tyler-frazier/intro_data_science/main/data/city_persons.csv"
pns = pd.read_csv(url, sep=",")
pns.dropna(inplace=True)
pns['age'] = pns['age'].astype(int)
pns['edu'] = pns['edu'].astype(int)
X = pns.drop(["wealthC"], axis=1)
y = pns.wealthC
Execute a K-nearest neighbors classification method on the data. What model specification returned the most accurate results? Did adding a distance weight help?
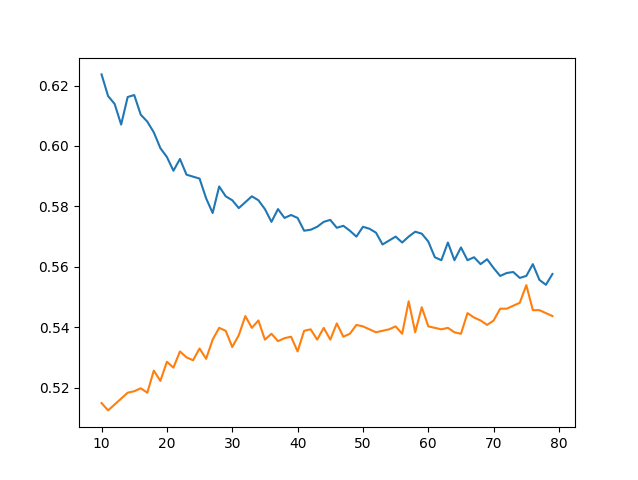
In this first step, I ran the data through the KNN classifier with a range of 10 - 80. It seemed that as the value of k increased, the training and testing scores slowly converged. The resulting training score was 0.6237 at k = 10, and the testing score was 0.5540 at k = 75. Thus the model was overfit. The relationship between the k value and resulting train (blue line) / test (orange line) scores can be seen in the following graph: Plot 1
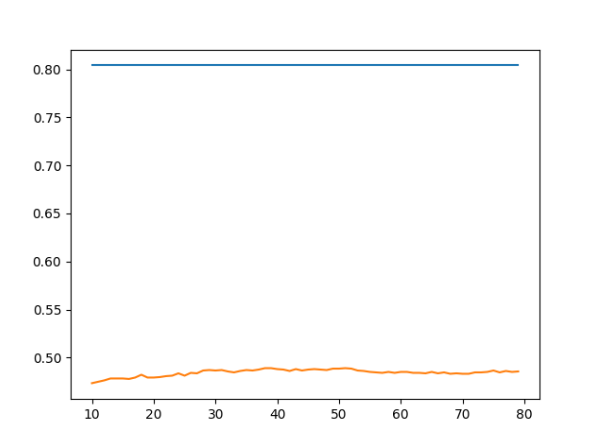
Rerunning the KNN classifier with a distance weight did change our results. The resulting training score increased to 0.8040 while the testing score decreased to 0.4890. The effects of this distance weight on our scores can be seen in the following graph with training scores in blue and testing in orange: Plot 2
Execute a logistic regression method on the data. How did this model fair in terms of accuracy compared to K-nearest neighbors?
Next, I ran a linear regression to detemine its relative efficacy in analyzing our data. The training score I got from the linear regression was 0.5495 while the testing score was 0.5505. Although the resulting model was only slightly underfit, it had comparable and perhaps even less efficacy than the KNN classifier above.
Next execute a random forest model and produce the results. See the number of estimators (trees) to 100, 500, 1000 and 5000 and determine which specification is most likely to return the best model. Also test the minimum number of samples required to split an internal node with a range of values. Also produce results for your four different estimator values by both comparing both standardized and non-standardized (raw) results.
Next I ran the data through a random forest model with estimators of 100, 500, 1000, and 5000. Although all four estimators resulted in a training score of 0.79134, their testing scores were more distributed. The 1000 estimator was the best, producing a testing score of 0.50122. Following this, the 500 and 5000 were the next best with very similar testing scores, 0.49780 and 0.49585 respectively. The least effective estimator was 100 with a testing score of 0.49488. Because all testing scores were significantly lower than the shared training score, all models produced were significantly overfit.
The minimum number of samples required to split an internal node within a range of 20 - 30 was determined to be 25. This produced trainaing and testing scores that were much closer together. Training values ranged from 0.63640 to 0.65690 while testing values ranged from 0.54563 to 0.55344, a decent bump when compared to previous results.
Standardizing the data had the following results on the efficacy of our models:
100 estimator Standardized: 0.48316
100 estimator Unstandardized: 0.47145
500 estimator Standardized: 0.49536
500 estimator Unstandardized: 0.47535
1000 estimator Standardized: 0.50073
1000 estimator Unstandardized: 0.48267
5000 estimator Standardized: 0.49292
5000 estimator Unstandardized: 0.48316
Repeat the previous steps after recoding the wealth classes 2 and 3 into a single outcome. Do any of your models improve? Are you able to explain why your results have changed?
I recoded welath class 2 and 3 into a single outcome with the following code:
pns['wealthC_adj'] = np.where((pns['wealthC'] == 2)(pns['wealthC'] == 3), 2.5, pns['wealthC'])
pns['wealthC_adj'] = pns['wealthC_adj'].astype(int)
X = np.array(pns.drop(["wealthC"], axis=1).drop(["wealthC_adj"], axis=1))
y = np.array(pns.wealthC_adj)
Next, I reran the KNN, linear, and random forest models with the new wealth classes. The resulting testing scores were:
KNN: 0.55969
Linear: 0.53021
100 estimator Standardized: 0.548889385
100 estimator Unstandardized: 0.54363178
500 estimator Standardized: 0.54845267
500 estimator Unstandardized: 0.546940445
1000 estimator Standardized: 0.54023178
1000 estimator Unstandardized: 0.54688805
5000 estimator Standardized: 0.55114761
5000 estimator Unstandardized: 0.54267465
When compared to the previous models before the recoding, the testing score of the KNN and random forest models increased. In contrast, the testing score of the linear model decreased slightly. The increases in the testing scores of most models could be caused by the decreased variability of our data as a result of combining welath classes.
Which of the models produced the best results in predicting wealth of all persons throughout the large West African capital city being described? Support your results with plots, graphs and descriptions of your code and its implementation. You are welcome to incorporate snippets to illustrate an important step, but please do not paste verbose amounts of code within your project report. Avoiding setting a seed essentially guarantees the authenticity of your results. You are welcome to provide a link in your references at the end of your (part 2) Project 5 report.
All of the recoded models, besides linear, were more efficient models than those before the recoding. The most effective of the models before recoding was the unweighted KNN model with a testing score of 0.5540. The graphs from the first part show this. Even after recoding, the KNN model remained the most efficient in explaining our data, with a testing score of 0.55969. While the recoded results from the random forest model are comparable to these results they are slightly less effective.
{kind=link}
{kind=link}